It is often useful when getting the maximum and minimum of eigenvalues of a diagonal matrix.ax2+2bxy+cy2ax2+by2+cz2+2dxy+2exz+2fyz=(xy)(acbd)(xy)=(xyz)⎝⎛adedbfefc⎠⎞⎝⎛xyz⎠⎞
Mainly, the symmetric matrix is used as above, the important note is that the symmetric matrix is not necessary so. Other matrices can be used for this, but the symmetric matrix is convenient since it has useful properties. However, it may occur the symmetric matrix is not available, and in that case, still this form can be derived. More specifically, the general representation is as follows. ax2+by2+cz2+2dxy+2exz+2fyz=(xyz)M⎝⎛xyz⎠⎞,M=⎝⎛m11m21m31m12m22m32m13m23m33⎠⎞⟹m11=a,m22=b,m33=c,m12+m21=2d,m13+m31=2e,m23+m32=2f
But, let A be the symmetric matrix from the above representations from now. Consider an eigenvector v and an eigenvalue λ of a matrix A, which is Av=λv. Then, vtAv=vtλv=λvtv. Therefore, λ=vtvvtAv
Especially, when ∥v∥=1, λ=vtAvt. As such, the maximum and minimum of eigenvalues can be produced from vtAvt. Meanwhile, as if a quadratic expression can be rotated to remove its cross-terms such as xy, the diagonalization of a matrix acts as deleting these cross-terms. From this perspective, the principal axis theorem appears which introduces a transformation of quadratic forms used in the beginning. Let λi be an eigenvalue of the symmetric matrix A. Then, the transformation is as follows. ax2+2bxy+cy2=kax2+by2+cz2+2dxy+2exz+2fyz=k⟹λ1x2+λ2y2=k⟹λ1x2+λ2y2+λ3z2=k
2. Diagonal Matrix
For a matrix A∈Rn×n, A is called diagonalizable if there exists an invertible matrix P and a diagonal matrix D such that D=P−1AP. Such P and D are not unique, and A and D are called similar. There are some conditions to be diagonalizable as follows.
The algebraic multiplicity is equal to the geometric multiplicity.
Assume that the characteristic polynomial of A is f(λ)=(λ−α)m(λ−β)⋯ for 1<m<n. Although the algebraic multiplicity of λ=α is m, it shoud be checked if dimker(A−αI)=m. Since dimker(A−αI)+rank(A−αI)=nas mentioned in this note, A is diagonalizable if n−rank(A−αI)=m.
Furthermore, A and D=P−1AP have the following properties in common.
∣A∣=∣D∣,
A and D have the same eigenvalues, ranks, and invertibility,
A and D do not always have the same eigenvectors.
3. Key Properties of Symmetric Matrices
For a symmetric matrix A∈Rn×n, all eigenvalues are real numbers. For example, let A=(abbc) and I=(1001). Also, let λ is an eigenvalue of A. Then, the discriminant D can be obtained as follows. ∣A−λI∣⟹D=(a−λ)(c−λ)−b2=λ2−(a+c)λ+ac−b2=0=(a+c)2−4(ac−b2)=(a−c)2+4b2≥0
Therefore, all eigenvalues of A are real numbers. Meanwhile, the correspondent eigenvectors for different eigenvalues of A are perpendicular, so A can be diagonalized. Let v1 and v2 be the correspondent eigenvectors for λ1=λ2, which means Av1=λ1v1 and Av2=λ2v2. Considering that x⋅y=xty for x,y∈Rn×1 and At=A, λ1(v1⋅v2)=(λ1v1)⋅v2=Av1⋅v2=(v1tAt)v2=v1tAv2=v1t(λ2v2)=λ2(v1tv2)=λ2(v1⋅v2)
This implies that (λ1−λ2)(v1⋅v2)=0. Since λ1=λ2, v1⋅v2=0. As such, the correspondent eigenvectors are perpendicular. Other key properties can be listed as follows. Let B be also a symmetric matrix. Then, the following statements hold.
A2, A3, and A+B are also symmetric.
(A2)t=AtAt=AA=A2, (A+B)t=At+Bt=A+B.
AB is always not symmetric if AB=BA. Otherwise, AB is symmetric.
(AB)t=BtAt=BA=AB.
If A is invertible, A−1 is symmetric.
(A−1)t=(At)−1=A−1.
4. Skew-Symmetric Matrix
For a matrix A∈Rn×n, A is skew-symmetric when At=−A. Besides, if A is a skew-symmetric matrix and invertible, then A−1 is skew-symmetric as well. Other than these, there are ways to induce a skew-symmetric matrix from any square matrix. (A−At)t=At−A=−(A−At)⟹A−At is skew-symmetric
Note that, similarly, A+At and AtA are symmetric. Therefore, it implies that any square matrix A can be represented with the sum of a symmetric matrix and a skew-symmetric matrix. A=21(A+At)+21(A−At)=(symmetric matrix)+(skew-symmetric matrix)
5. Trace Properties
Other than the obvious properties of the trace, there are two things to remember. For square matrices A and B, and an invertible square matrix P,
tr(AB)=tr(BA),
tr(A)=tr(B) when B=P−1AP,
tr(A)=λ1+⋯+λn, that is, the trace of A is the sum of all eigenvalues of A.
Although AB=BA, the traces of them are the same. Besides, when A and B are similar, the traces of them are the same as well. It implies that any transformation after a coordinates change keeps the trace if it comes back to the original coordinates.
6. Determinant Consistency
For a matrix A∈Rn×n, the determinant of A denotes the volume of n-dimensional parallelopiped. As mentioned in this note, shape deformation of this parallelopiped does not change its original volume. Let A=(a1⋯an) for column vectors ai∈Rn×1. If ai=v1+v2, detA=∣A∣=∣(a1⋯v1⋯an)∣+∣(a1⋯v2⋯an)∣
7. Determinant of a Block Matrix
Given block matrices A∈Rn×n, B∈Rm×m, C∈Rm×n, and D∈Rn×m,
∣∣ACOB∣∣=∣A∣∣B∣,
∣∣DBAO∣∣=(−1)nm∣A∣∣B∣,
where O is a zero matrix. Note that this does not imply ∣∣ACBD∣∣=∣A∣∣D∣−∣B∣∣C∣.
8. Area of Polygons
For a matrix A=(a1⋯an)∈Rm×n whose column vectors are ai∈Rm×1, the area of the polygon determined from these column vectors is ∣detAtA∣
9. Rank Properties
rank(At)=rank(A)=rank(AtA) for a matrix A∈Rm×n.
rank(AB)=rank(B)=rank(BA) if a matrix A is invertible for A,B∈Rn×n.
10. Orthogonal Projection
Let Projab be the projection of b on a. Then, Projab=∥b∥∥a∥∥b∥a⋅b∥a∥a=(∥a∥2a⋅b)a
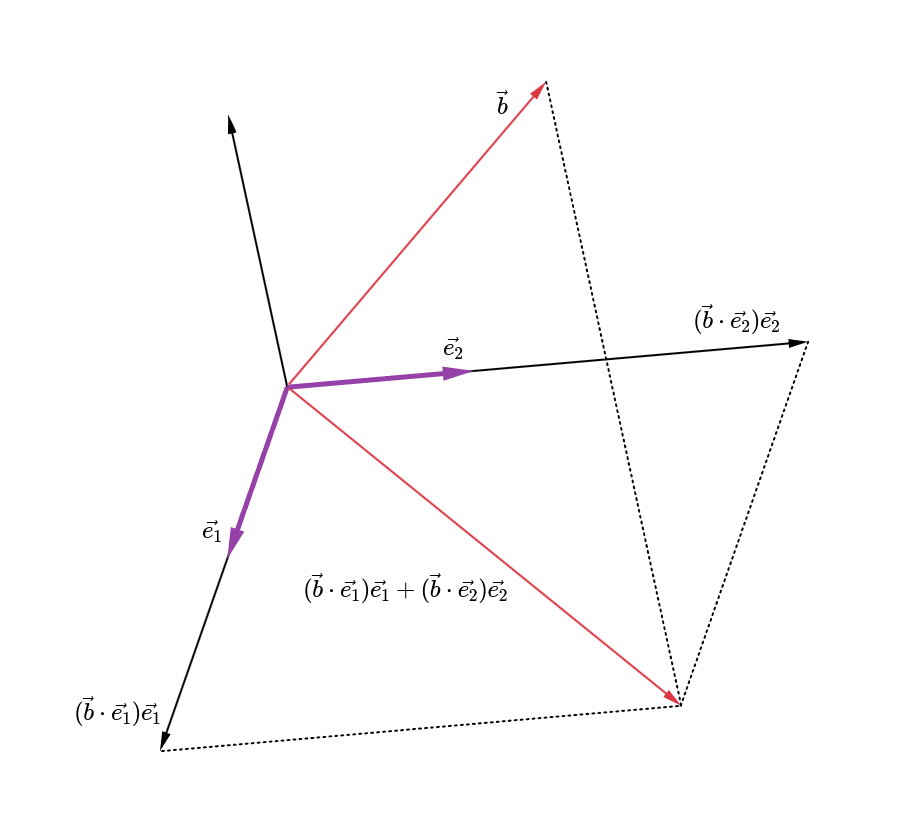
Here, the coefficient of this projection vector is called Fourier coefficient. Moreover, for a matrix A∈Rm×n whose column vectors are a basis of a vector space W, the projection of b on WProjWb=Ab=A(AtA)−1(Atb)=(b⋅e1)e1+⋯+(b⋅en)en
where {e1,⋯,en} is an orthogonal basis of W. Note that A(AtA)−1At is the standard matrix of this orthogonal projection. Let this standard matrix be P. Then, Pt=P which means P is symmetric. Also, P2=P which means the projected point keeps the same place after projecting again as mentioned in this note. For example, for a vector b∈R3×1, its projection on the plane W is as below figure.
11. Cross Product
Other than the basic features, there are things to remember.
Triple product a⋅(b×c)=b⋅(c×a)=c⋅(a×b) means that the volume of the parallelepiped defined by the three vectors. So, the volume of the tetrahedron is ∣a⋅(b×c)∣/6.
a×(b×c)=(a⋅c)b−(a⋅b)c=(a×b)×c, so it is not associative.
By Lagrange’s identity, (a×b)⋅(c×d)=(a⋅c)(b⋅d)−(a⋅d)(b⋅c).
Interestingly, ∥a×b∥2+(a⋅b)2=∥a∥2∥b∥2.
12. Cayley-Hamilton Theorem
For a matrix A∈Rn×n and the identity matrix I of size n, let D(λ)=∣A−λI∣. By observation, D(A)=0. In other words, A is a root of the characteristic equation f(λ)=∣A−λI∣=0. Here, f(A)=0 is called the Cayley-Hamilton theorem. This theorem leads to the inverse matrix of A as follows. Define the characteristic equation f(λ)=λn+an−1λn−1+⋯+a1λ+a0I=0. Then, f(A)⟹A−1f(A)⟹A−1=An+an−1An−1+⋯+a1A+a0I=0=An−1+an−1An−2+⋯+a1I+a0A−1=0=a01(−An−1−an−1An−2−⋯−a1I)
13. Transformations
Finding a symmetric point about a line y=(tanθ)x
(cos2θsin2θsin2θ−cos2θ)
Finding a projected point about a line y=(tanθ)x
(cos2θsinθcosθsinθcosθsin2θ)
Finding a symmetric point about a plane n⋅x=0 where n is the normal
I−2ntnnnt
Finding a projected point about a plane n⋅x=0 where n is the normal
I−ntnnnt
14. Jacobian
As if the substitution method in a definite integral causes the size of variables to change such as x2=t→2xdx=dt, the substitution method in a double integral makes the region area change. Therefore, this difference must be compensated, which is what the Jacobian determinant does. Meanwhile, geometrically the Jacobian determinant also means the instantaneous rate of change of area. Suppose f:Rn→Rm is a function such that each of its first-order partial derivatives exists on Rn. This function takes a point x∈Rn as input and produces the vector f(x)∈Rm as output. Then the Jacobian matrix J∈Rm×n is defined as follows. J=⎝⎛∇tf1⋮∇tfm⎠⎞=⎝⎛∂x1∂f1⋮∂x1∂fm⋯⋱⋯∂xn∂f1⋮∂xn∂fm⎠⎞
where ∇tfi is the transpose of the gradient of the i-th component. Now, assume that x=f(u,v) and y=g(u,v). Then, the Jacobian determinant is ∣J∣=∣∣∂(u,v)∂(x,y)∣∣=∣∣xuyuxvyv∣∣=∣∣∂(x,y)∂(u,v)∣∣1=∣∣uxvxuyvy∣∣1
Moreover, if ∣J∣=0, there exists a functional relationship between x and y. As such, the transformation is not invertible, which means that there is no way to get x and y back from u and v. Similarly, assume that x=f(u,v,t), y=g(u,v,t), and z=h(u,v,t). Then, the Jacobian determinant is ∣J∣=∣∣∂(u,v,t)∂(x,y,z)∣∣=∣∣xuyuzuxvyvzvxtytzt∣∣
Again, if ∣J∣=0, there exists a functional relationship between x, y, z. As such, the transformation is not invertible, which means that there is no way to get x, y, z back from u, v, t.
Keep going!Keep going ×2!Give me more!Thank you, thank youFar too kind!Never gonna give me up?Never gonna let me down?Turn around and desert me!You're an addict!Son of a clapper!No wayGo back to work!This is getting out of handUnbelievablePREPOSTEROUSI N S A N I T YFEED ME A STRAY CAT