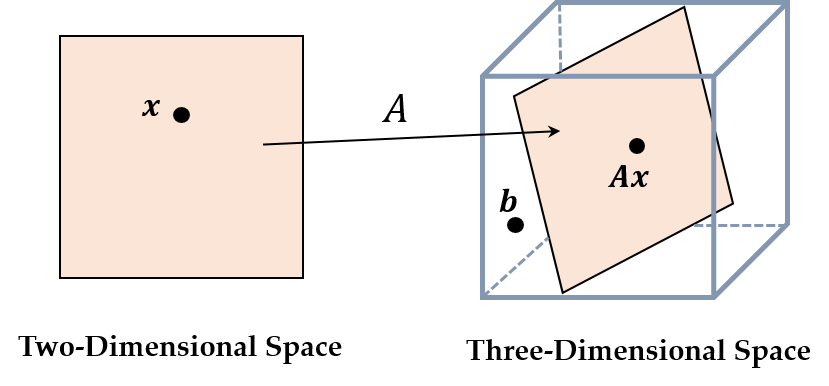
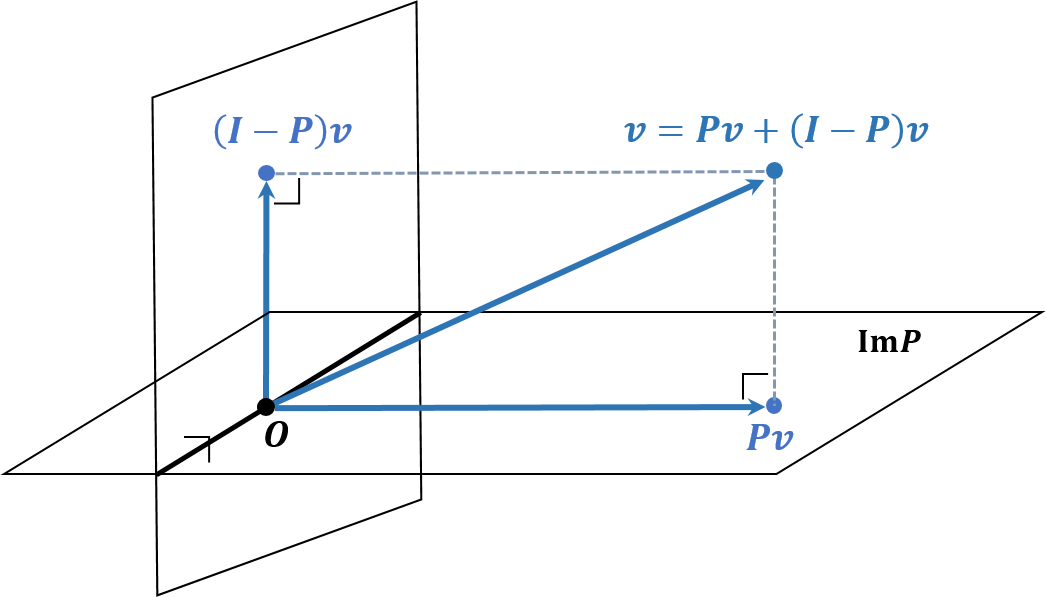For an m×n matrix A and a vector b∈Rm, the linear system Ax=b is to find the optimal solution x∈Rn.
The Residual Minimization
The problem Ax=b can be replaced by the problem minimizing the residual, ∥b−Ax∥22. Let Ai be the i-th row vector of A. Then the cost function f(x) can be defined as follows. f(x)=∥b−Ax∥22=∥∥⎝⎛b1−A1tx⋮bm−Amtx⎠⎞∥∥22=k∑(bk−Aktx)2
A necessary condition for a minimum is that x be a critical point of f, where the gradient vector ∇f(x) is zero. Let aij be the (i,j) element of A. Then, ∂xi∂f=k∑2(bk−Aktx)∂xi∂(bk−Aktx)=2k∑(bk−Aktx)(−aki)=0⟹k∑akiAktx=k∑akibk=(a1i⋯ami)⎝⎛A1t⋮Amt⎠⎞x=(a1i⋯ami)⎝⎛b1⋮bm⎠⎞⟹⎝⎛a11a1n⋯⋮⋯am1amn⎠⎞⎝⎛A1t⋮Amt⎠⎞x=⎝⎛a11a1n⋯⋮⋯am1amn⎠⎞⎝⎛b1⋮bm⎠⎞⟹AtAx=Atb
This equation is called normal equation. Moreover, AtA is positive (semi-)definite because xtAtAx=(Ax)t(Ax)=∥Ax∥22≥0, so it minimizes f. Especially, if ∥Ax∥22=0, it tells that there is no x such that Ax=0 except x=0. It also means that A is nonsingular whose column vectors are linearly independent. Therefore, the solution of AtAx=Atb is the same as the optimal solution of Ax=b when A is nonsingular.
Another Approach When m>n
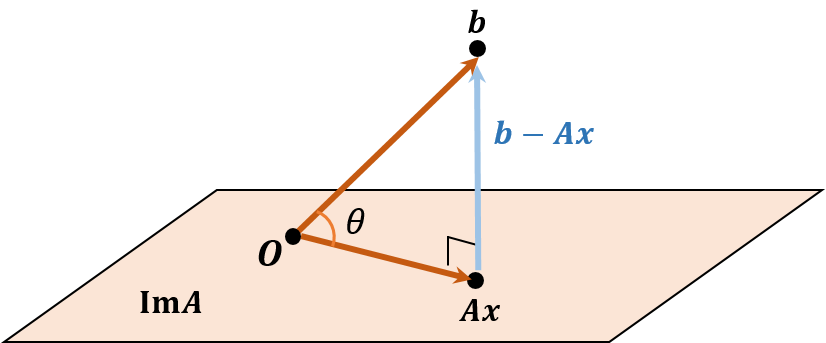
In this case, A maps the lower dimension to the higher dimension. For example, when m=3 and n=2, there may be a point b in the objective space that Ax cannot completely cover.
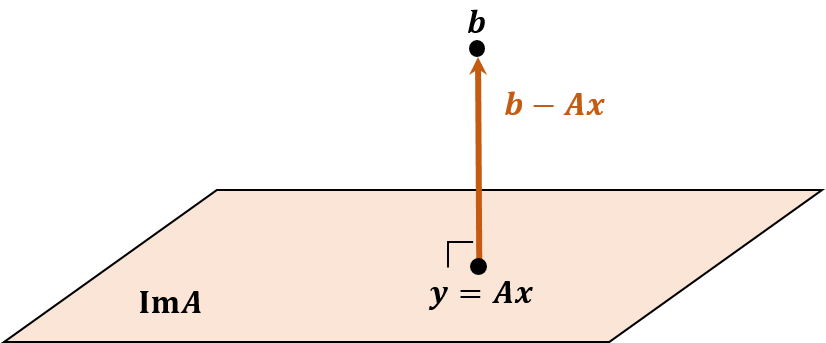
So, the linear system Ax=b cannot be solved exactly. However, finding the point closest to b might be a good approximation. Let y=Ax be the closest point to b.
When y is closest to b, the vector b−y=b−Ax is parallel to the normal of the hyperplane ImA. Besides, Ae1,⋯,Aen are the basis of ImA where e1,⋯,en are the standard basis of the original space. In other words, it implies that column vectors of A are the basis of ImA, which means they are all perpendicular to b−Ax. Therefore, At(b−Ax)=0, and it yields the normal equation. Accordingly, the normal equation estimates the optimal solution of Ax=b even though there exists no the exact solution.
Another Approach Using Projector
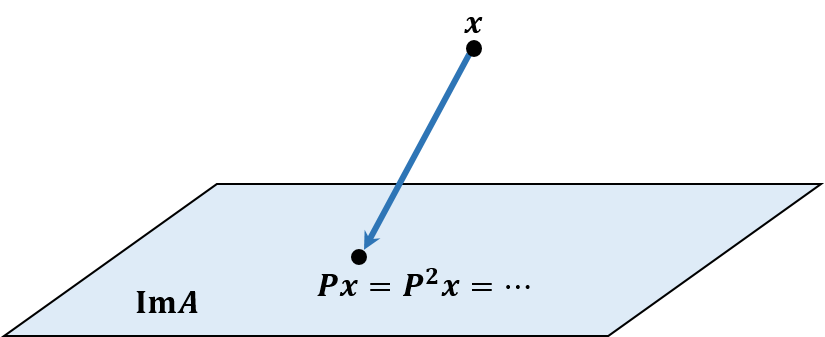
A square matrix P is called a projector if it is idempotent, which means P2=P. Such P projects any vector to ImP but leaves unchanged any vector that is already on ImP. If P is symmetric, it is called an orthogonal projector, and I−P is also an orthogonal projector to a hyperplane perpendicular to ImP. Obviously, (I−P)2=I−2P+P2=I−P. More specifically, for any vector v=Pv+(I−P)v, (Pv)t((I−P)v)⟹=vtPt(v−Pv)=vtP(v−Pv)=vtPv−vtP2v=vtPv−vtPv=0Pv⊥(I−P)v
Now, assume that P is an orthogonal projector onto span(A) such that PA=A. Then the cost function f(x) can be derived as follows. f(x)=∥b−Ax∥22=∥P(b−Ax)+(I−P)(b−Ax)∥22=∥P(b−Ax)∥22+∥(I−P)(b−Ax)∥22=∥Pb−PAx∥22+∥(I−P)b−(I−P)Ax∥22=∥Pb−Ax∥22+∥(I−P)b∥22
Note that (I−P)A=0 since PA=A. The second term does not depend on x, so the residual norm is minimized when x is chosen so that the first term is zero. Pb−Ax=0⟹At(Pb−Ax)=AtPb−AtAx=AtPtb−AtAx=(PA)tb−AtAx=Atb−AtAx=0
Therefore, it produces the normal equation as well.
Evaluation
The solution from the normal equation can be evaluated by the condition number and angle between b and Ax. The condition number of A tells how close A is a singular matrix. However, if m=n, A is not invertible, so the pseudoinverse A+=(AtA)−1At should be introduced. In this case, the condition number of A is Cond2(A)=∥A∥2∥∥A+∥∥2
Meanwhile, as the angle between b and Ax is smaller, b is closer to Ax, so it is a good measure to find whether the solution is well-conditioned. This angle can be obtained as cosθ=∥Ax∥2/∥b∥2.
Reference
[1] Michael T. Heath, Scientific Computing: An Introductory Survey. 2nd Edition, McGraw-Hill Higher Education.
Keep going!Keep going ×2!Give me more!Thank you, thank youFar too kind!Never gonna give me up?Never gonna let me down?Turn around and desert me!You're an addict!Son of a clapper!No wayGo back to work!This is getting out of handUnbelievablePREPOSTEROUSI N S A N I T YFEED ME A STRAY CAT