The conjugate gradient method is the most popular iterative method for solving large systems of linear equations. This is effective for systems of the form Ax=b where x is an unknown vector, b is a known vector, and A is a known, square, symmetric, positive-definite matrix. This form is mostly used to find the minimum of a cost function f(x). Since A is a symmetric and positive-definite matrix, f(x) is shaped like a paraboloid bowl, so it has a minimum as mentioned in this note. If A might be singular, in which case no solution is unique. In this case, the set of solutions is a line or hyperplane having a uniform value for f. If A is indefinite, the gradient descent and conjugate gradient methods will likely fail.
Eigenvectors & Eigenvalues
Consider an eigenvector v and an eigenvalue λ of a matrix B such that Bv=λv. Iterative methods often depend on applying B to a vector over and over again. When B is repeatedly applied to an eigenvector v, one of two things can happen. If ∣λ∣<1, then Biv=λiv will vanish as i approaches infinity. If ∣λ∣>1, then Biv will grow to infinity. Each time B is applied, the vector grows or shrinks according to the value of ∣λ∣.
If B is symmetric, then all different eigenvectors of B are perpendicular. That is, all eigenvectors form a basis for Rn. As such, any n-dimensional vector can be expressed as a linear combination of these eigenvectors. Applying B to x that is not an eigenvector is equivalent to applying B to the eigenvectors and summing the result.
Conjugate Gradient Method
The conjugate gradient method is especially suitable for very large problems since it does not require explicit second derivatives. Indeed, it does not even store an approximation to the Hessian matrix. While the gradient descent method tends to search in the same directions repeatedly, leading to very slow convergence, the conjugate gradient method avoids repeatedly searching the same directions by modifying the new gradient at each step to remove components in previous directions. The resulting sequence of conjugate search directions implicitly accumulates information about the Hessian matrix as iterations proceed. Compare that the gradient descent method follows a zigzag path, which appears because each gradient is orthogonal to the previous gradient.
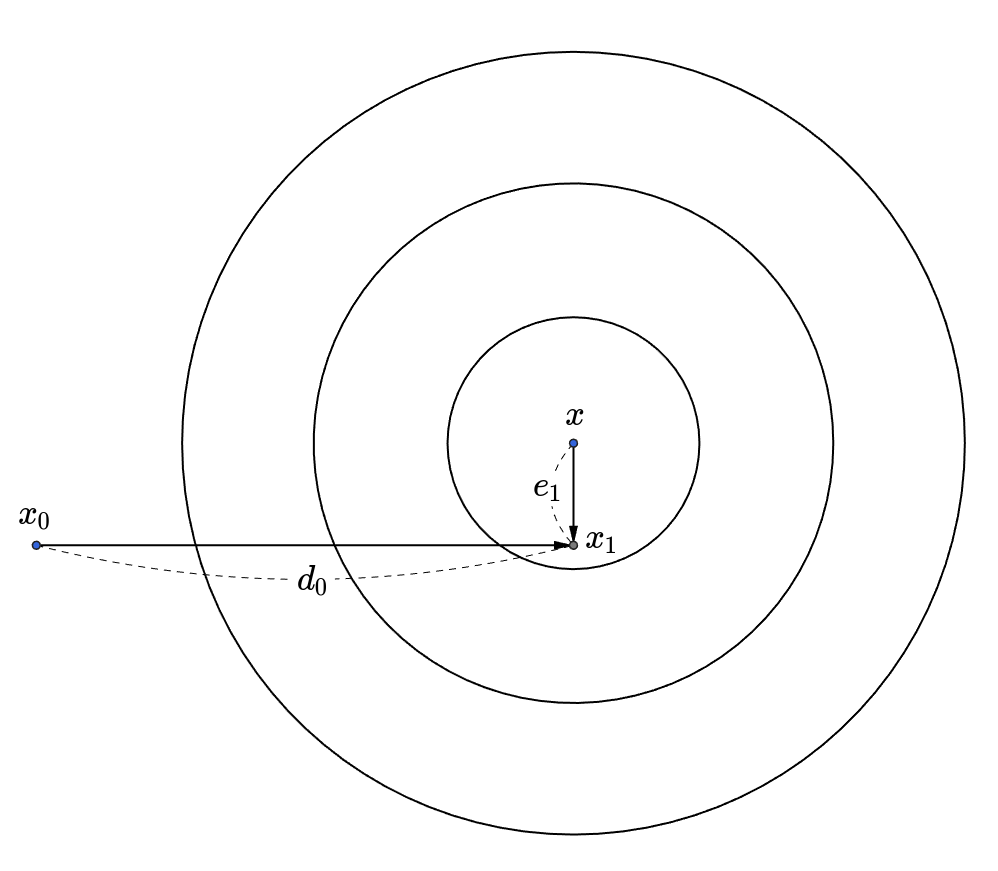
Here is the idea behind this method. Suppose that d0,d1,⋯,dn−1 are a set of orthogonal search directions whose each search direction is used for exactly one step. Let x1,⋯,xn be the estimated solutions by step starting from the initial guess x0. Also, let the error in i-step be ei=xi−x to indicate how far from the solution x. Then, ei+1 should be orthogonal to di so that di will never be used again. Using this fact, xi can be updated along with αi per one-iteration where αi is a line search parameter that indicates how big a step takes. ⟹⟹xi+1=xi+αididitei+1=dit(xi+1−x)=dit(xi+αidi−x)=dit(ei+αidi)=0αi=−ditdiditei
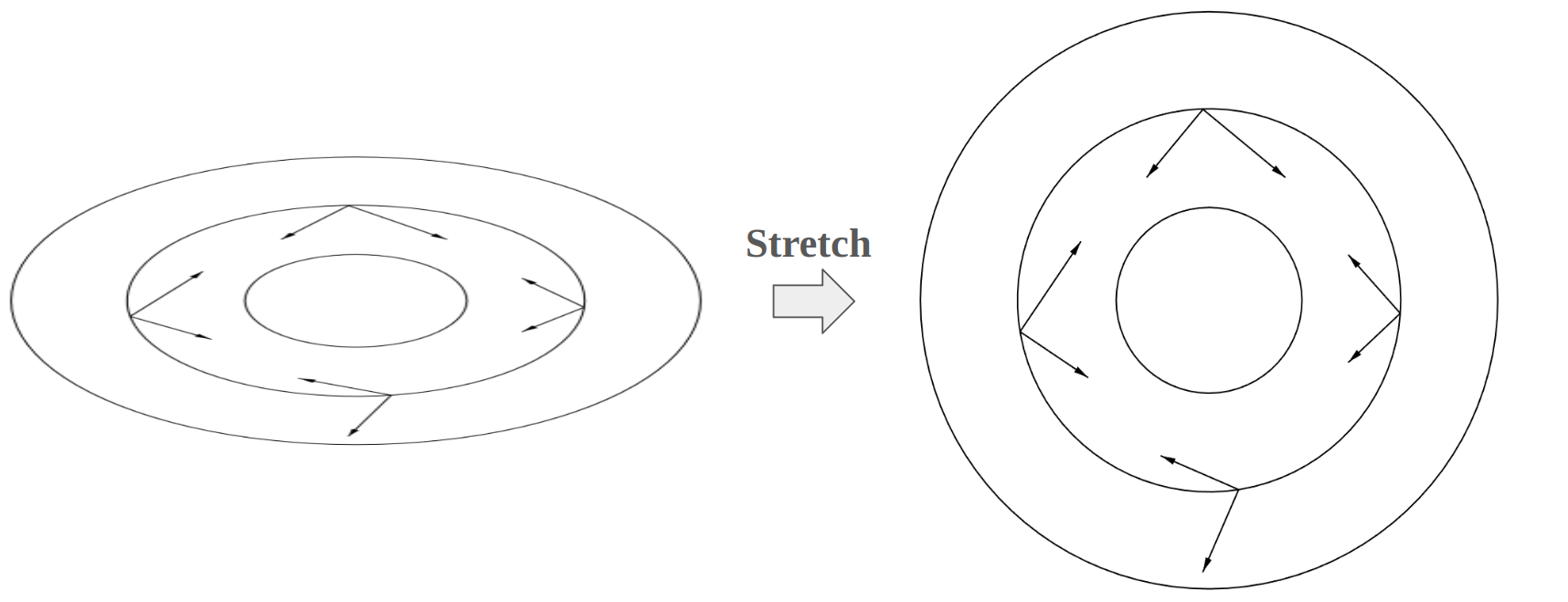
However, the contradiction occurs αi requires ei to update xi and ei needs the solution x. The workaround is to make the search directions mutually A-orthogonal. Vectors y and z are called A-orthogonal if ytAz=0, or conjugate. That is, y is orthogonal to the transformed z by A. As shown below, the main idea is to stretch the ellipses to appear circular. In this perspective, ei+1 should be A-orthogonal to di this time.
Considering that the residual ri=b−Axi=Ax−Axi=−Aei which indicates how far from the correct value of b, ditAei+1=ditA(xi+1−x)=ditA(xi+αidi−x)=ditA(ei+αidi)=ditAei+αiditAdi=−ditri+αiditAdi=0⟹αi=ditAdiditri
Gram-Schmidt Conjugation
Then how can the search directions be obtained? The conjugate Gram-Schmidt process makes it simple to generate them. Recalling the Gram-Schmidt process, it is a method of constructing an orthonormal basis from a linearly independent set of vectors. More specifically, di can be constructed from a set of n linearly independent vectors u0,⋯,un−1 as follows. d0d1d2di=u0,=u1−(u1⋅d0)d0,=u2−(u2⋅d0)d0−(u2⋅d1)d1,⋮=ui−k=0∑i−1(ui⋅dk)dk
Note that these should be normalized later. But, how is this formula derived? This is based on the orthogonality. ⟹⟹di=ui+k=0∑i−1βikdk0=di⋅dj=ui⋅dj+k=0∑i−1βik(dk⋅dj)=ui⋅dj+βij(dj⋅dj)=ui⋅dj+βij(i>j)βij=−ui⋅dj
The same logic is used for the conjugate Gram-Schmidt process. This is based on the A-orthogonality this time. ⟹⟹di=ui+k=0∑i−1βikdk0=ditAdj=uitAdj+k=0∑i−1βikdktAdj=uitAdj+βijdjtAdj(i>j)βij=−djtAdjuitAdj
Then how can the set {u0,⋯,un−1} selected? It is possible by setting ui=ri, that is, by conjugation of the residuals. This choice makes sense because the residual has the nice property that it is orthogonal to the previous search directions. In other words, it is guaranteed always to produce a new, linearly independent search direction unless the residual is zero, in which case the problem is already solved. djtri=−djtAei=−djtA(xi−x)=−djtA(xi−1+αi−1di−1−x)=−djtA(ei−1+αi−1di−1)=djtri−1−αi−1djtAdi−1=⋯=djtrj−k=j∑i−1αkdjtAdk=djtrj−αjdjtAdj=djtrj−djtrj=0(i>j)
Note that the residual has the recurrence property. As each residual is orthogonal to the previous search directions, it is also orthogonal to the previous residuals. That is, ritrj=0 when i=j. dj=uj+k=0∑j−1βjkdk⟹0=djtri=ujtri+k=0∑j−1βjkdktri=ujtri=rjtri(i>j,uj=rj)
As another important property, the following identity updates αi. ditri=uitri+k=0∑i−1βikdktri=uitri=ritri⟹αi=ditAdiditri=ditAdiritri
Only New Search Direction
Since the search directions can be obtained from the conjugate Gram-Schmidt process, the final update function can be set up as well. From the recurrence of the residual checked previously, rj+1=rj−αjAdj, ritrj+1ritAdjβij=ritrj−αjritAdj⟹αjritAdj=ritrj−ritrj+1=⎩⎨⎧αiritri−αi−1ritri0(i=j)(i=j+1)otherwise=−djtAdjuitAdj=−djtAdjritAdj=⎩⎨⎧αi−11di−1tAdi−1ritri0(i=j+1)(i>j+1)
Note that βij is defined only when i>j. This result shows that most of the βij terms have disappeared. It is no longer necessary to store old search directions to ensure the A-orthogonality of new search directions. This major property reduces the space and time complexities per iteration to O(m), where m is the number of nonzero entries of A. Simplyfing βi,i−1 further, αi=ditAdiritri⟹βi,i−1=αi−11di−1tAdi−1ritri=ri−1tri−1ritri
As a result, the conjugate gradient method can be summed up as follows. ⎩⎨⎧d0=r0=b−Ax0αi=ditAdiritrixi+1=xi+αidiri+1=ri−αiAdiβi+1,i=ritriri+1tri+1di+1=ri+1+βi+1di
Then how to choose a starting point, and when to stop? If a rough estimate of the value of x is available, it can be used as the starting point x0. If not, set x0=0. This will eventually converge when used to solve linear systems. Nonlinear minimization is trickier, though, because there may be several local minima. Usually, it is customary to stop when the norm of the residual falls below a specific value such as ∥ri∥<ϵ∥r0∥.
Preconditioning
Thd conjugate gradient method can still converge very slowly if A is ill-conditioned. Preconditioning is a technique for improving the condition number of a matrix. Suppose that M is a symmetric, positive-definite matrix that approximates A, but is easier to invert. Then, Ax=b can be indirectly solved by solving M−1Ax=M−1b because M−1A is relatively well-conditioned. If the eigenvalues of M−1A are better clustered than those of A, this system can be iteratively solved more quickly than the original problem. But, M−1A is not generally symmetric nor definite, even if M and A are. To avoid this difficulty, E can be obtained such that EEt=M by Cholesky factorization since M is positive-definite. Then, M−1A and E−1AE−t have the same eigenvalues. Let v be an eigenvector of M−1A with eigenvalue λ. (E−1AE−t)(Etv)=E−1Av=(EtE−t)E−1Av=EtM−1Av=λEtv
With this fact, the system Ax=b can be transformed into Ax=b⟹E−1Ax=E−1b⟹(E−1AE−t)Etx=E−1b⟹(E−1AE−t)x^=E−1b
So, x can be obtained after solving it for x^=Etx first. Note that E−1AE−t is symmetric and positive-definite. Then, the transformed preconditioned conjugate gradient method as follows. A^=E−1AE−t,b^r^0=E−1b−(E−1AE−t)Etx0d^itA^d^j=d^itE−1AE−td^j=0=E−1b,x^=Etx=E−1(b−Ax0)⟹r^0=E−1r0⟹di=E−td^i⟹d^i=Etdi
The difficulty is that E must be computed. However, there is a way to avoid this computation. Considering that r^itr^i=ritE−tE−1ri=ritM−1ri since E−tE−1=M−1, the untransformed preconditioned conjugate gradient method is finally updated as follows. ⎩⎨⎧r0=b−Ax0d^0=r^0⟹d0=E−tE−1r0=M−1r0αi=d^itA^d^ir^itr^i=ditEE−1AE−tEtdiritM−1ri=ditAdiritM−1rixi+1=xi+αidiri+1=ri−αiAdiβi+1,i=r^itr^ir^i+1tr^i+1=ritM−1riri+1tM−1ri+1di+1=M−1ri+1+βi+1di
As shown above, E disappear and only M−1 is required. The effectiveness of a preconditionerM is determined by the condition number of M−1A, and occasionally by its clustering of eigenvalues. The problem remains of finding a preconditioner that approximates A well enough to improve convergence enough to make up for the cost of computing M−1ri once per iteration. Intuitively, preconditioning is an attempt to stretch the quadratic form to make it appear more spherical so that the eigenvalues are close to each other. A perfect preconditioner is M=A which makes M−1ri have a condition number of one, and the quadratic form is perfectly spherical, so the solution takes only one iteration.
The simplest preconditioner is a diagonal matrix whose diagonal entries are identical to those of A, known as diagoanl preconditioning or Jacobi preconditioning, which is scaling the quadratic form along the coordinate axes. By comparison, the perfect preconditioner M=A scales the quadratic form along its eigenvector axes.
A more elaborate preconditioner is incomplete Cholesky preconditioning. While the Cholesky factorization finds L such that A=LLt, incomplete Cholesky factorization finds L^ such that A≈L^L^t where L^ might be restricted to have the same pattern of nonzero elements as A and other elements of L are thrown away. To use L^L^t as a preconditioner, the solution to L^L^tw=z is computed by backsubstitution. Unfortunately, incomplete Cholesky preconditioning is not always stable.
Normal Equation
What if A is not square, not symmetric, and not positive-definite? In this case, the normal equation should be applied, which means that the solution can be found from the linear system AtAx=Atb. If A is square and nonsingular, the solution is the same as the one of Ax=b. If A is not square, and Ax=b is overconstrained, then there may or may not be a solution to Ax=b, but it is always possible to find x closest to the solution. If Ax=b is not underconstrained, then AtA is nonsingular since AtA is symmetric and positive-definite, and the conjugate gradient method can be used to solve this normal equation. However, note that the condition number of AtA is the square of that of A, so convergence is significantly slower.
Nonlinear Conjugate Gradient Method
As explained in this note, suppose that f is a function for x∈Rn and its Hessian matrix Hf is positive definite. By Taylor’s theorem, f(x+s)≈f(x)+∇f(x)ts+21stHf(x)s
That is, x should be moved by ∥s∥ in direction s. However, the direction to move in the case of the conjugate gradient method is already fixed as d. As such, what to know is how much x should be moving by. More specifically, α such that s=αd should be selected. To find α, the approximated equation should be differentiated against α, not s this time, unlike the original process mentioned in this note. αdtHf(x)d=−∇f(x)td
Keep going!Keep going ×2!Give me more!Thank you, thank youFar too kind!Never gonna give me up?Never gonna let me down?Turn around and desert me!You're an addict!Son of a clapper!No wayGo back to work!This is getting out of handUnbelievablePREPOSTEROUSI N S A N I T YFEED ME A STRAY CAT