Auto-Calibration

PHOTO BY SNAPWIRE
As the world is projected on our eyes, the objects in the world can be projected on the image plane of a camera. For this projection, the intrinsic and extrinsic matrix of the camera are required to render the image plane. In other words, if the shape of objects in the 3D world is already defined, estimating what it looks like on the image plane is related to these matrices.
Especially, finding out the intrinsic matrix is about camera calibration which can be done with or without some materials such as a chessboard. Simply put, it helps to decide which color is proper to be painted in each pixel of the image plane. I wanted to research this work for the 3D reconstruction project which is the one of my personal projects. For that, I needed some calibration methods processed automatically which are more technically called auto-calibration.
Requirement
Before describing the details, I have to determine what information I will use if I do not want to use any added materials like a chessboard. I assumed that we already knew about the actual heights of humans in meters and the bounding boxes of them in camera frames. In most cases, people can be easily observed in the place where cameras are installed, for example, for detecting or tracking people in computer vision and graphics. That is why I chose the human information to calibrate cameras. More specifically, I assumed that the average height of people is 1.8 meters and the bounding boxes whose shape is rectangle were already available. Moreover, the camera is considered being set on the flat ground.
Problem Definition
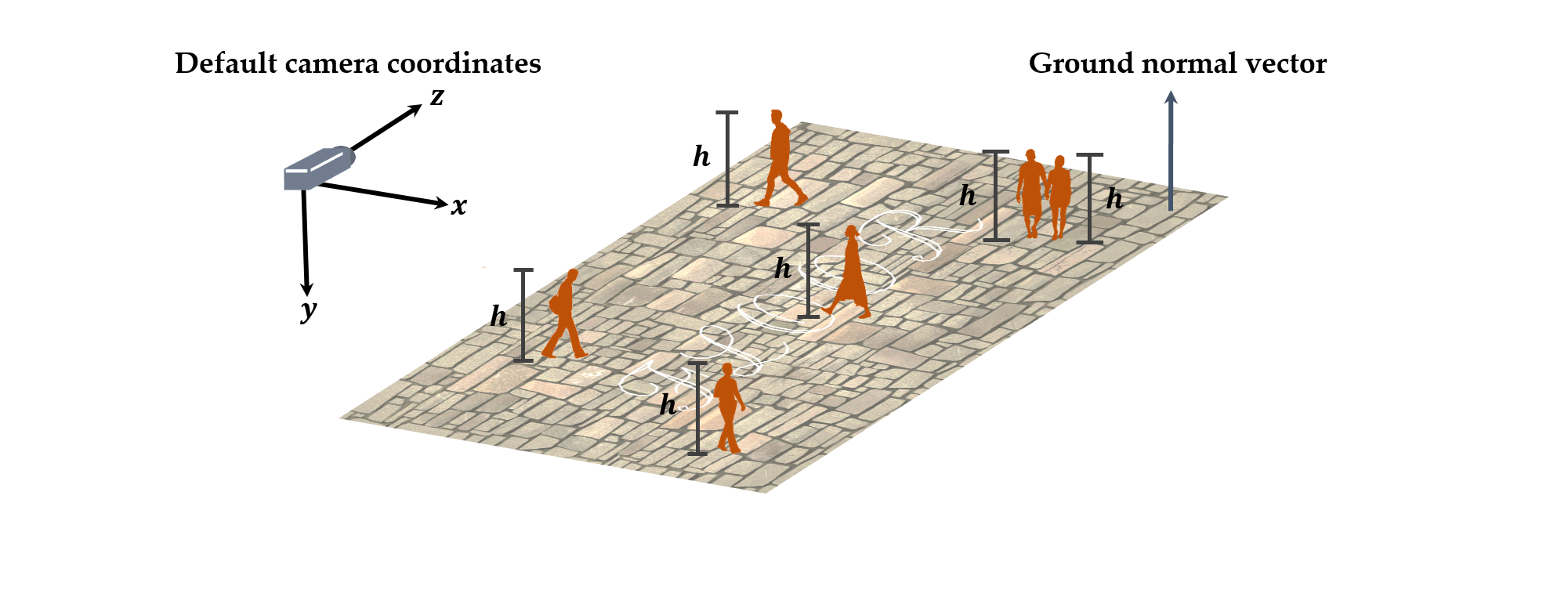
Although we do not know about the tilt angle of the camera, it is required that the default camera coordinates is defined. As above, I set the coordinates as its z-axis is parallel with the ground and its y-axis is perpendicular to the ground. If the tilt angle is not zero, the z-axis which is the camera view vector intersects at a point on the ground. Let the tilt angle , then the ground normal vector is , so the ground plane equation is where is the camera height from the ground in meter. In addition, people detected are interpreted as two points which are the top point and the bottom point in 3D camera coordinates. In this case, the distance between and is the human height that we already defined as 1.8 meters. Finally, the intrinsic camera matrix can be defined as follows:
where is the focal length, and are the half of the camera width and height. Meanwhile, these points are projected on the camera as and . Now, and can be written as follows:
Cost Functions
The parameters to estimate about the unknown camera are the focal length, the tilt angle and the height from ground. The pan angle is always considered zero because the default camera coordinates can be set so that zero-pan angle is satisfied. The roll angle is ignored in this work.
1. x-axis: the top point can be projected on the ground as the bottom one.
At first, we can imagine that the top and bottom points in 3D camera coordinates are transformed to the default camera coordinates whose tilt angle is zero. In the default camera coordinates, it is reasonable that the top point can be projected on the ground as the bottom one although it is possible that people do not always stand upright and the top and bottom points are distorted in camera view. Therefore, the components of the top and bottom points in the default camera coordinates should be the same, which allows the following cost function:
2. y-axis: the top point is -meter high from the bottom one.
Second, we already assume that the human height is -meter high which is 1.8 meters, so it can be used for another cost function. The components of the top point in the default camera coordinate is -meter higher than that of the bottom one. It induces the following cost function:
3. z-axis: the top and bottom points have the same depth.
Third, it is natural that the top and bottom points in the default camera coordinates have the same depth although the human head can get ahead of its foot a little or vice versa. It means that the final cost function can be written as follows:
These three cost functions represent for only one human sample, but it can be applied for many samples using summation of each cost function, which is the more natural situation. When samples are summed, norm or norm can be used. Besides, it is not necessary that these cost functions should be used when the only one parameter is unknown. It can be solved through the simple calculation, not the estimation because each cost function can be reformed for the unknown parameter although it will be more complex.