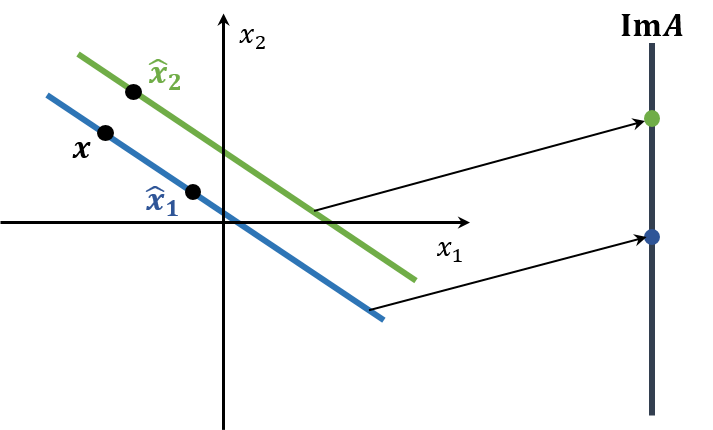Consider the following linear system: Ax=(0.9130.4570.6590.330)x=(0.2540.127)=b
Let the estimated solutions be x1^ and x2^, x1^=(−0.08270.5),x2^=(0.999−1.001)
and its residuals are ∥r1∥1∥r2∥1=∥b−Ax1^∥1=2.1×10−4=∥b−Ax2^∥1=2.4×10−2
Since ∥r1∥<∥r2∥, it seems that x1^ is the optimal solution. Considering the real solution, however, is x=(1,−1)t, it makes more sense that the optimal solution would be x2^.
This situation happens because A is close to singular. Therefore, when A is ill-conditioned, which means the condition number of A is large (>104), this can happen.
When A is close to a singular matrix, a line in the original space is almost suppressed to a point in the objective space. So, x2^ which is close to the optimal solution x in the original space may be mapped further than x.
Actually, the residual r=b−Ax^ is the transformed error by A into the same space as b for the error e=x^−x. This is because r=b−A(e+x)=−Ae. Therefore, the small residual does not imply a small error, and it depends on A.
Reference
[1] Michael T. Heath, Scientific Computing: An Introductory Survey. 2nd Edition, McGraw-Hill Higher Education.
Keep going!Keep going ×2!Give me more!Thank you, thank youFar too kind!Never gonna give me up?Never gonna let me down?Turn around and desert me!You're an addict!Son of a clapper!No wayGo back to work!This is getting out of handUnbelievablePREPOSTEROUSI N S A N I T YFEED ME A STRAY CAT