Suppose that β is the radix, or base, p is precision, and [L,U] is the range of exponent E. Then for x∈R, x=±(d0.d1d2…dp−1)ββE=±(d0+βd1+β2d2+⋯+βp−1dp−1)βE
where di is an integer in [0,β−1].
p-digit number based-βd0d1…dp−1: mantissa, or significant
d1…dp−1 of mantissa: fraction
E: exponent, or characteristic
2. Normalization
For x=0∈R, it can be normalized so that d0=0 and mantissa m is in [1,β). This normalization is unique and saves space for leading zeros. Especially, d1 is always 1 when β=2, so it does not have to ve stored and saves, in turn, one bit more.
The number of the normalized floating-point number x is
In general, floating point numbers are not uniformly distributed. However, they are uniformly distributed in the exponent range [E,E+1) for E∈Z. In this range, the minimal difference between numbers which floating-point system can represent is (0.0…1)ββE=β1−pβE=βE−p+1. If this range is changed to [E+1,E+2), then the minimal difference is multiplied by β.
Let the minimal difference between numbers which floating-point system can represent in [L,L+1) be ϵ. Then the following shows the entire distribution of floating-point numbers.
The negative part is symmetrically the same as the positive one. Note that there could be the integers which the floating-point system cannot represent when this interval ϵβk>1.
3. Subnormal(Denormalized) Numbers
When looking the series the floating-point system represents, there is empty space in [0,βL]. This range can be divided by ϵ, which is the interval in [L,L+1). Then the number in this range can be represented as d0=0 and d1=0, that is, ±(0.d1…dp−1)ββL if some condition are satisfied which will come later.
4. Rounding
The number which the floating-point system can exactly represent is called machine number. However, the number the system cannot do should be rounded. There are rules for rounding such as chopping or round-to-nearest method. Here are some examples about these rules when p=2. number1.6491.6501.6511.699chop1.61.61.61.6round-to-nearest1.61.61.71.7number1.7491.7501.7511.799chop1.71.71.71.7round-to-nearest1.71.81.81.8
The round-to-nearest is also known as round-to-even, because it rounds the number to the one whose last digit is even in case of a tie. This rule is the most accurate and unbiased, but expensive. Meanwhile, IEEE standard system has the round-to-nearest as the default rule.
5. Machine Epsilon (Machine Precision)
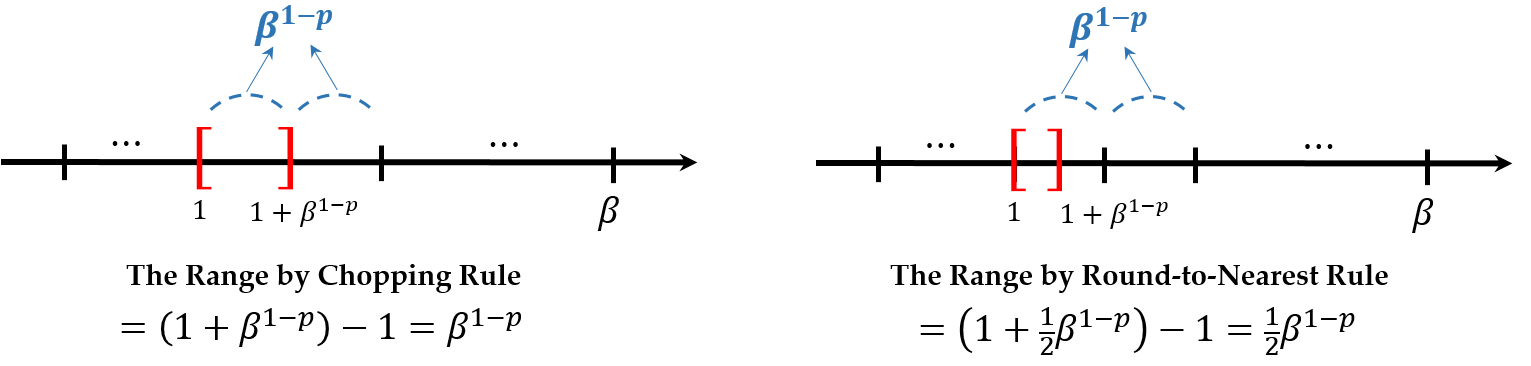
The floating-point system can be measured by the machine epsilon, machine precision, or unit roundoff which is denoted by ϵmach. It is the minimal number so that 1+ϵmach>1. Considering that the interval between the floating-point numbers in [1,β) which can be exactly represented is β1−p because E=0,
ϵmach=β1−p with rounding by chopping, and ϵmach=2β1−p with rounding-to-nearest. Now, consider the floating-point x that can be exactly represented. Then there are many numbers that can be rounded to x.
Therefore, the relative errors can be calculated as follows: ∣relative error∣≤⎩⎨⎧∣∣xβE−p+1∣∣=(d0.d1…dp−1)βEβE−p+1≤β1−p(chopping)∣∣x21βE−p+1∣∣=(d0.d1…dp−1)βE21βE−p+1≤21β1−p(round-to-nearest)
It means that ∣relative error∣≤ϵmach.
6. IEEE Floating-Point Format
This system has β=2, p=24, L=−126, and U=127 for 32-bit floating-point numbers.
Note that d0 is always 1 since β=2, so 23-bit mantissa can store only 23-bit for d1…d23 with p=24. Its exponent is 8-bit, so is in [0,255], but it is biased by −127. It yields that L≤E−127≤U, so 1≤E≤254. Therefore, it can represent some special values when E=0 or E=255. ⎩⎨⎧1≤E≤254⟹±(1.d1…d23)22E−127normalizedE=0{mantissa=0⟹±(0.d1…d23)22−126subnormalmantissa=0⟹±0E=255{mantissa=0⟹NaNmantissa=0⟹±∞
This results can be found here as well. Even though IEEE standard system uses the round-to-nearest as the default rounding rule, std::numeric_limits<float>::epsilon() returns 2−23 because single precision floating-point cannot represent 2−24. So, in general, ϵmach=2−23. It has about 7-precision in decimals. logϵmach=log2−23≈−23×0.3010=−6.923=−7+α,α∈[0,1)⟹ϵmach=2−23=10−7+α
7. ULP (Units in the Last Place)
Consider two floating-point numbers which are identical in all respects except for the value of the least-significant bit in their mantissas. These two values are said to differ by 1 ULP. The actual value of 1 ULP changes depending on the exponent. 1.0f has an unbiased exponent zero, and a mantissa in which all bits are zero(except for the implicit leading 1). For this value, 1 ULP is equal to ϵmach=2−23. In general, if a floating-point value’s unbiased exponent is x, then 1 ULP =2xϵmach.
Mathematically, the condition a≥b is equivalent to the condition a+1 ULP >b. As a little trick, it is possible to implement ≤ and ≥ only using < and > by adding or subtracting 1 ULP to or from the value being compared.
References
[1] Michael T. Heath, Scientific Computing: An Introductory Survey. 2nd Edition, McGraw-Hill Higher Education
[2] J. Gregory, Game Engine Architecture, Third Edition, CRC Press
Keep going!Keep going ×2!Give me more!Thank you, thank youFar too kind!Never gonna give me up?Never gonna let me down?Turn around and desert me!You're an addict!Son of a clapper!No wayGo back to work!This is getting out of handUnbelievablePREPOSTEROUSI N S A N I T YFEED ME A STRAY CAT