Slower Multithreading
- Cach Line Bouncing (Cache Ping-Pong) — Sharing the same variable
- False Sharing — Sharing the same cache line
perf- References
Multithreading is not always faster than single threading. In such cases, it is necessary to investigate whether the cache is the cause of the problem. The typical characteristics of the cache are cache lines and protocols. Here, line or block is the minimum unit of information transfer in the cache. This is due to spatial locality, which means that when a program accesses data, it is likely to access adjacent data next time. This means that it is efficient to retrieve a “bundle” of data that includes nearby data rather than just the requested data. Additionally, the protocol refers to a cache coherence protocol, which is described in this note.
Cach Line Bouncing (Cache Ping-Pong) — Sharing the same variable
// Code1
atomic<int> a;
void increase()
{
for (int i = 0; i < 500'000'000; ++i) {
++a;
}
}
void run()
{
thread t1 = thread( increase );
thread t2 = thread( increase );
t1.join();
t2.join();
}
// Code2
int a;
void run()
{
for (int i = 0; i < 1'000'000'000; ++i) {
++a;
}
}
Code1 may seem to run faster because it uses multithreading, but Code2 may run faster. A possible scenario is the cache protocol.
If Code1 is executed on Core1 and Core2, then a is copied in the cache of each core. If Core1 adds 1 to a, Core2’s copy must be invalidated. As a result, a in Core2’s cache is no longer up-to-date. In other words, the cache bouncing occurs. Similarly, if Core2 adds 1 to a, an invalidate message is sent to Core1, and the cache bouncing occurs again. That is why it is also called the cache ping-pong.
If the overhead of maintaining cache coherency is so great that it impedes the overall flow, performance may be worse than for the single-threaded program.
False Sharing — Sharing the same cache line
// Code1
struct data { int a; int b; };
struct data global_data;
void increaseA()
{
for (int i = 0; i < 500'000'000; ++i) {
++global_data.a;
}
}
void increaseB()
{
for (int i = 0; i < 500'000'000; ++i) {
++global_data.b;
}
}
void run()
{
thread t1 = thread( increaseA );
thread t2 = thread( increaseB );
t1.join();
t2.join();
}
// Code2
struct data { int a; int b; };
struct data global_data;
void run()
{
for (int i = 0; i < 500'000'000; ++i) {
++global_data.a;
}
for (int i = 0; i < 500'000'000; ++i) {
++global_data.b;
}
}
Code1 may seem to run faster because it uses multithreading and does not share the same variable this time, but Code2 may run faster.
In fact, the two threads in Code1 do not share any variables, but it is very likely that these two variables are in the same cache line. When Core1 updates a variable, it sends an invalidate message to Core2 for the entire line containing that variable. In other words, the cache bouncing can still occur. This is a problem called false sharing.
One solution is to use padding. The size of the cache line is generally 64 bytes, and 64 bytes of padding can be added between variables a and b.
struct data
{
int a;
int padding[16];
int b;
}
Then the two variables will no longer be in the same cache line. Of course, if there are other variables in the structure, and the size of the variable is larger than the cache line, this variable can be placed between a and b, instead of using additional padding.
In a portable manner, C++17 introduced a constant called std::hardware_destructive_interference_size, which returns the minimum recommended offset to avoid cache line sharing. This value can be used in combination with the alignas keyword.
perf
The perf tool in Linux can analyze running programs. The perf stat command shows statistics on various key information that appears during execution.
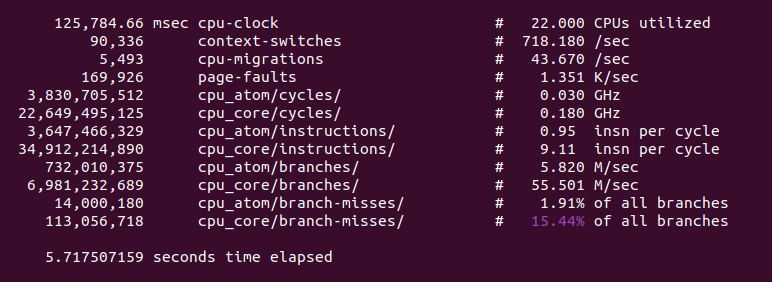
In the above example, the insn per cycle entry tells how many machine instructions the CPU executes in the program it runs in one clock cycle. This is only one of many factors that affect execution speed, and it does not mean that this entry is the sole reason for the execution speed of the program.
References
[1] 루 샤오펑. 2024. 컴퓨터 밑바닥의 비밀, 길벗
[2] Marc Gregoire. 2021. Professional C++, Fifth Edition. John Wiley & Sons, Ltd.