Compiler and Linker
Compiler
The compiler transforms a high-level language program into a low-level language program. It produces an object file from a source file via an assembly code.
Header
Header files are not seen by the compiler. Instead, the C++ preprocessor replaces each #include statement with the contents of the corresponding header file. Each included header file is similarly scanned and #include directives nested within these headers are processed recursively. Conceptually, the resulting text forms an intermediate, source-level module called a translation unit, as a file with a .i suffix. Note that this .i file is hypothetical and not likely to be produced by a compiler unless specifically requested.
This intermediate representation is then fed to the C++ compiler, which compiles the translation unit and produces a corresponding object file. Header files exist as distinct files from the point of view of the programmer, but thanks to preprocessor’s header file expansion, all the compiler needs to see are translation units.
Process
Step 1. Lexical Analysis
The first thing a compiler does is go through the source code and find all the tokens. Examples of tokens are reserved words, names, operators, and punctuation symbols. For example, the tokens from int a = 1; may look like
T_Keyword int
T_Identifier a
T_Assign =
T_Int 1
T_Semicolon ;
Each line represents one token. The left column starting with T indicates the token meaning, and the right column indicates the value that the token has. This process of extracting tokens from source code is called lexical analysis.
Step 2. Syntax Tree
Simply listing tokens is of no use. It needs to be processed to understand the intent that the programmer is trying to convey.
while (expression) {
code to iterate ...
}
For example, when the compiler finds the token of the while keyword, it waits for the next token (. Otherwise, the compiler reports a syntax error. On the other hand, if it passes this process successfully, it knows that the next token must be a bool expression and waits for that. It then repeats the process of waiting and processing ) and { until it finally encounters }. This process is called parsing. The structure that the compiler parses and interprets is expressed as a tree, which is called a syntax tree.
Step 3. Semantic Analysis
After the syntax tree is generated, it must be checked for any errors. For example, a string cannot be added to an integer value, and the value types on the left and right of the comparison symbol cannot be different. If this step is passed, it is proven that there are no compile errors, and this process is called semantic analysis.
Step 4. IR, Assembly, Machine Code
The compiler generates a more refined form, which is called intermediate representation code (IR code), based on the results of the syntax tree traversal. In some cases, additional optimizations are performed on the IR code. Once this process is complete, the IR code is converted into assembly code, and finally into machine instructions.
This machine instruction data is saved in a .o file. The file with the .o extension is called the object file.
Linker
For every source file, there is a corresponding object file. If the project becomes more complex and there are N source files, there will be N object files. However, since only one executable is needed, there must be something that combines these N object files into one executable. The linker is responsible for this.
Analogy
The entire process of linking is similar to having multiple authors each write chapters separately and then gather them to publish one book. Here, a published book can be thought of as the executable file. The important features of how the linker works are as follows.
Symbol Resolution
For a book to be completed without errors, each chapter must be organized so that the material it references is actually contained within the book. The linking process is similar: there must be exactly one actual implementation of an external symbol in any module. Then, the linker finds it and links it, and this process is called symbol resolution. Completing this process will ensure that there are no link errors.
Relocation
When quoting from one chapter to another, it should be mentioned which page it is from saying, for example, “For a detailed explanation of A, refer to page N.” However, at the time of writing this sentence, the content of A has not been written, so the author may not know which page is the page N. Therefore, for now, temporarily mark it as page N, and when finally start editing, once page N is determined, the entire manuscript must be updated by finding all the parts marked as page N. This process is called relocation.
Consider a certain source file references a print() function defined in another module. When the compiler compiles this source file, it does not know exactly where the function will be located in memory. So the compiler marks this function as N and moves on. Later, during the linking process, the linker checks these marks and puts them together to create an executable file, determines the exact address of the function, and replaces N with the actual memory address.
Compiler Passing the Work to the Linker
When the compiler encounters an externally defined global variable or function during the compile process, it will happily skip ahead to the next step, without caring whether the variable is actually defined or not, as long as there is a declaration for that variable. Finding the definition of the referenced variable is the job of the linker, not the compiler.
Although the compiler passes this work to the linker, it does something else to reduce the burden on the linker. It records information about which symbols can be referenced externally for each source file, and conversely, it also records which external symbols are referenced. This table is called a symbol table. The compiler stores this table in the object file.
Symbols refer to all variable names related to global variables and function names. Since local variables are only used within a module and cannot be referenced from external modules, they are not of interest to the linker.
However, it is difficult for the linker to resolve external symbols with only this information, and in reality, the compiler delivers more information. For example, when calling the externally defined function foo(), the compiler will simply record like
call 0x00
In addition, whenever it cannot determine the memory address, it stores the instruction in .relo.text and stores data related to the instruction in .relo.data. In the case of foo(), the compiler writes the following message to .relo.text while generating the call instruction: “The symbol foo was found at an offset of 60 bytes from the start address of the code segment, but it does not know memory address to execute.”
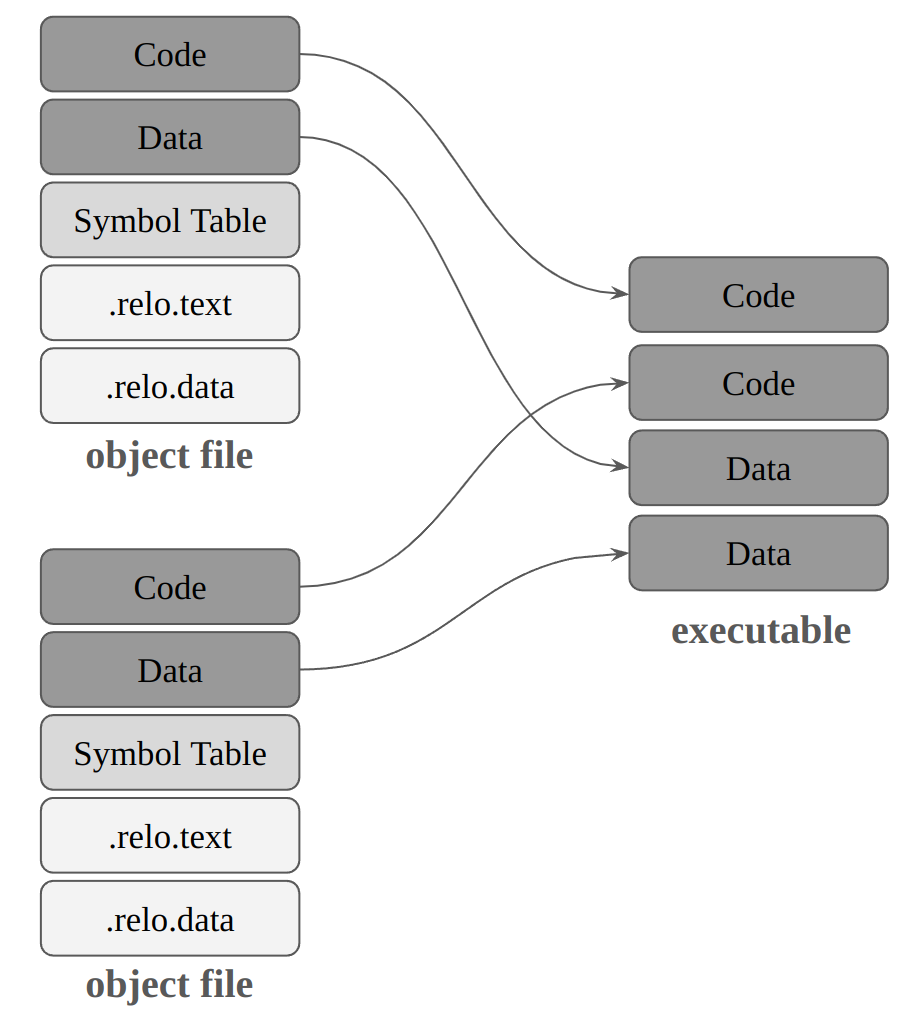
After the linker completes the symbol resolution step, it merges segments of the same type in each object file as in the figure above. Once combined, it can determine the memory addresses where all machine instructions and global variables will be located at program execution time.
Virtual Memory
But there is something strange. The machine code in an executable file is still relocatable. If something is relocatable, it means that the memory addresses have not yet been determined. In other words, the addresses of all instructions and data in the executable are still relative, not absolute. The final absolute memory address of the program is not known until the program is actually loaded into memory, just prior to running it. Then how could the linker resolve all the symbols?
How can the linker know the run-time memory address of a variable in advance? This is possible thanks to virtual memory. Virtual memory makes each program think that it has exclusive use of all its own memory while it is running. Since the linker knows the process memory structure, it can determine the memory address of a symbol in this virtual memory, without worrying about where it is located in actual physical memory. The memory management unit (MMU) translates this memory address into an actual physical memory address by referring to the page table.
Libraries
The linker creates a single executable file from multiple object files. Libraries written by other people may also be linked during this process.
Static Library
Multiple source files can be individually compiled and linked in advance to create a static library. When creating an executable file, the precompiled static library is copied to the executable file as is during the linking process without the need for recompilation. However, the statically linked program keeps using the old version even though a new version is released because the library routines become part of the executable code. To use the new version, the program depending on that static library must also be recompiled each time. In addition, all routines in the library are loaded, even if those calls are not executed. Also, if a static library is 2 MB in size and there are 500 executables that use that library, then about 1 GB of data will be made up of duplicate data.
A static library is a collection of files that have been pre-grammar-checked and converted into object files. Therefore, programmers cannot know which functions or variables are included. So, header files used during compilation must be provided together. However, from the perspective of the programmer using it, it is impossible to know whether the functions or variables written in the header file are actually in the library file. What would happen if the function declaration section is written in the header but the function is not actually included in the built library file? It would be impossible to avoid link errors. In other words, the following suspicions may arise. “It is said to exist in the header file, but is it not actually in the lib file?”
Dynamic Library
With dynamic libraries, only essential information, such as the referenced dynamic library name, symbol table, and relocation information, is included in the executable file, unlike static libraries, which copy all library contents into the executable file. This significantly reduces the size of the executable file.
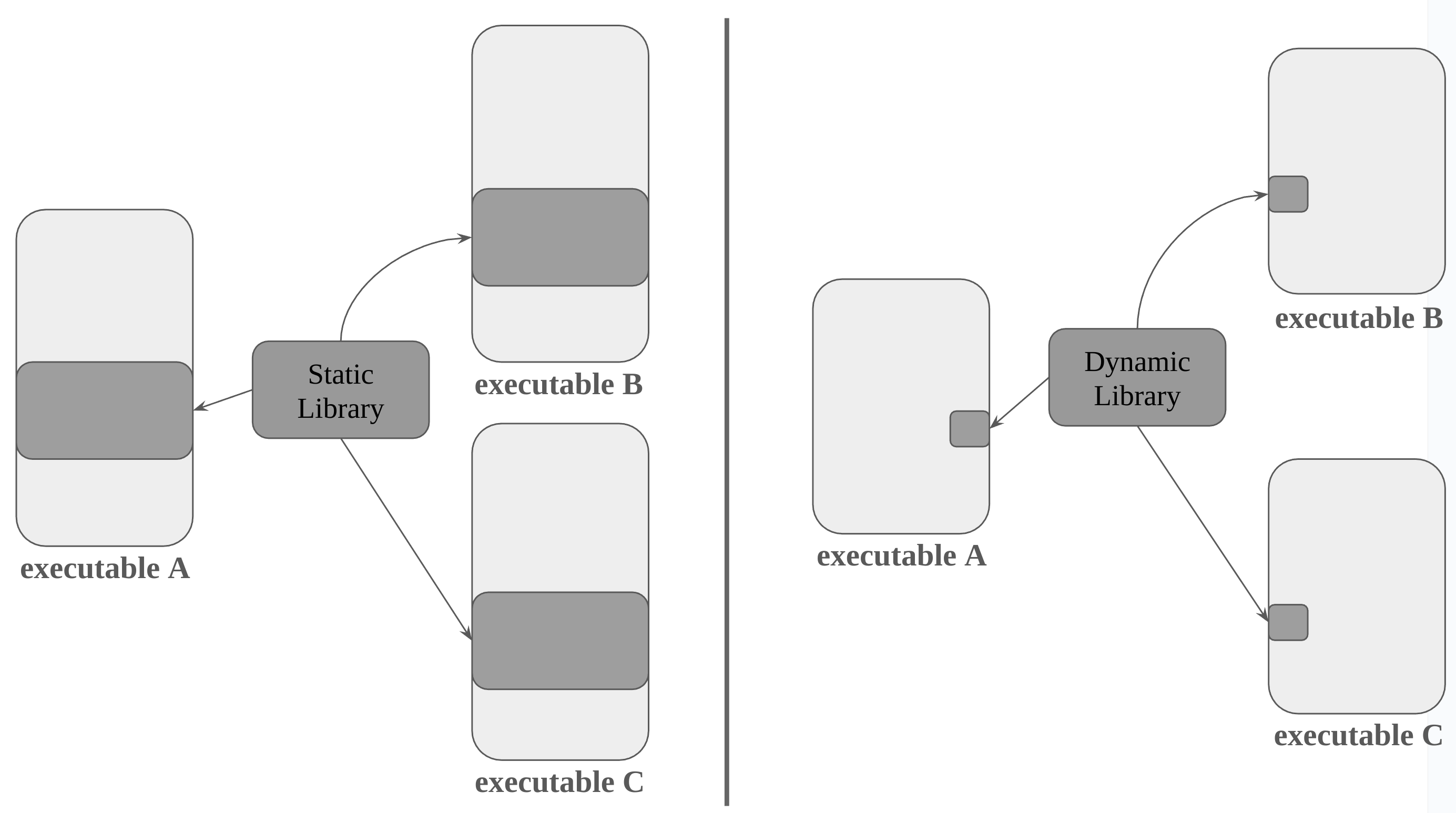
This essential information is stored in the executable as above. So when will this essential information be used? It is used when dynamic linking occurs. The dynamic linking is deferred until the program is run. There are two ways to do dynamic linking:
- Dynamic linking occurs at load time.
- After loading an executable, the loader can check whether the executable depends on a dynamic library. If a dynamic library is needed, a separate process called a dynamic linker is executed to complete the linking process by checking the existence and location of the referenced dynamic library and the memory location of the symbol.
- Using dynamic linking during load requires explicitly telling the compiler which dynamic libraries the executable references. For example, the following command compiles the source file
main.c, which depends onlibfoo.so, to produce an executable file calledpro.
gcc -o pro main.c /path/to/libfoo.so
- Dynamic linking occurs at run time.
- Runtime dynamic linking is a more dynamic linking method because the executable does not need to know what dynamic libraries it depends on until it runs.
- In this method, the dynamic library information is not stored inside the executable during creating the executable. Instead, the programmer can dynamically load the dynamic library directly whenever needed using a specific API in the code. For example, in Linux, functions such as
dlopen,dlsym, anddlclosecan be used. - It pays a good deal of overhead the first time a routine is called, but only a single indirect jump thereafter.
So where should the code and data of a dynamic library be placed in the process address space if they cannot be included in the executable file? They are placed in the free space between the stack area and the heap area, which means under the heap. Therefore, all threads within the process can use dynamic library code and data.
Dynamic libraries require recompiling only that dynamic library, even if the code is modified. However, since dynamic libraries are linked at load/run time, performance is slightly lower than when using static linking. Also, the code in a dynamic library is called position-independent code because it operates independently of a specific memory address. Position-independence means that no matter which process calls foo(), the exact execution address can be found.
How is this possible, even though dynamic libraries will have different address spaces when loaded into different processes? This is possible via mmap, and although it requires a more indirect approach, the benefits outweigh the losses, so it is acceptable.
In Linux,
lddcommand shows which dynamic libraries an executable depends on.
References
[1] 루 샤오펑. 2024. 컴퓨터 밑바닥의 비밀, 길벗
[2] J. Gregory, Game Engine Architecture, Third Edition, CRC Press
[3] J. Lakos, Large-Scale C++ Volume I: Process and Architecture, Addison-Wesley Professional
[4] 전상현. 2023. 아무도 알려주지 않은 C++ 코딩의 기술, 로드북