1. For an arbitrary sequence ann of certain elements numbered by two indices, the following holds.
i=1∑nj=1∑iaij=j=1∑ni=j∑naij
This arises from the following facts. This logic process is useful and can be applied to other similar problems. ⟺⟺1≤i≤n and 1≤j≤i1≤j≤i≤n1≤j≤n and j≤i≤n
2. Approximation of Harmonic Number
Harmonic number Hn is defined by Hn=1+21+31+⋯+n1=k=1∑nk1,n≥0
The approximate size of this harmonic number is a well-known quantity as follows. Hn=lnn+γ+2n1−12n21+120n41−ϵ,0<ϵ<252n61
where γ=0.5772156649… is Euler’s constant. Thus Hn is reasonably close to the natural logarithm of n.
3. n! is divisible by pμ where n is a natural number and p is a prime number, then μ is defined by
μ=k>0∑⌊pkn⌋
That is, n! is divided by pμ times. In other words, μ can be summed from the number of natural numbers having p-factor and the number of ones having p2-factor and so on. For example, when n=1000 and p=3, μ=⌊31000⌋+⌊91000⌋+⌊271000⌋+⌊811000⌋+⌊2431000⌋+⌊7291000⌋+0+⋯=333+111+37+12+4+1=498
It means that 1000! is divisible by 3498 and is not by 3499. ⌊n/pk+1⌋=⌊⌊n/pk⌋/p⌋ is useful for more simple calculation. With a similar logic to this note, this can be proved as follows. m=⌊pk+1n⌋⟺m≤pk+1n<m+1⟺mp≤pkn<(m+1)p⟺mp≤⌊pkn⌋<(m+1)p⟺m≤⌊pkn⌋/p<m+1⟺⌊⌊pkn⌋/p⌋=m
So, the k-th step can be used for the (k+1)-th step.
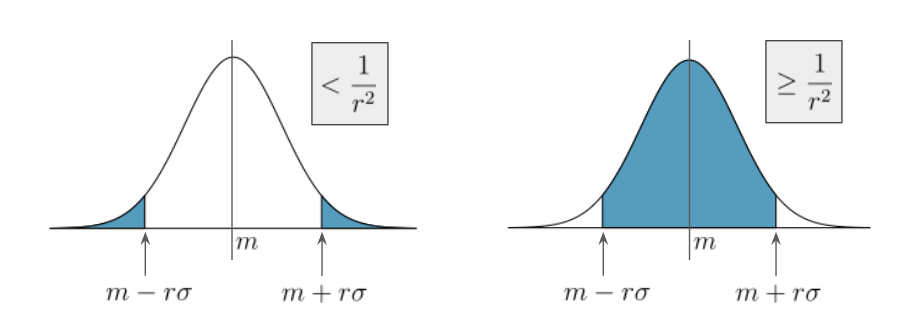
4. Chebyshev’s Inequality
For data X, let m be the mean of X and V be the variance, then standard deviation σ=V. σ is important from the fact that the probability of ∣xi−m∣>rσ is <1/r2 for any real number r≥1 and xi∈X. Let this probability be p and pi=P[X=i].
If p>0, V⟹=i∑(xi−m)2pi=∣xi−m∣>rσ∑(xi−m)2pi+∣xi−m∣≤rσ∑(xi−m)2pi>∣xi−m∣>rσ∑(rσ)2pi+0=(rσ)2∣xi−m∣>rσ∑pi=(rσ)2p=pr2Vpr2V<V⟹p<r21
5. The mean and variance are easily from the generating function.
Generating functionG can be used whenever to obtain information about a sequence of numbers an. By obtaining information from G, information from an can be obtained. G(z)=a0+a1z+a2z2+⋯=n≥0∑zn
Consider the probabilities pk=P[X=k] as a sequence and generating function G of them. Then, the mean m and variance V of G can be defined as follows. G(z)=p0m=k∑kpk,+p1z+p2z2+⋯,V=k∑k2pk−m2
Note that G(1)=p0+p1+p2+⋯=1. Considering G′(z), m can be represented as G′(z)⟹=p1+2p2z+⋯=k∑kpkzk−1,m=k∑kpk=G′(1)
6. The mean and variance of two generating functions are summations of each one of them.
Assume that G and H are generating functions for some probabilities, which means that G(1)=H(1)=1. Let m(X) and V(X) be the mean and variance of probabilities represented by a generating function X. Then, the following holds. m(GH)=m(G)+m(H),V(GH)=V(G)+V(H)
7. When running into the 0/0-form, consider Taylor’s theorem as a workaround.
Consider a uniform distribution whose probability is 1/n of obtaining the values 1, 2, ⋯, n. The generating function of this is G(z)G(1)G′(z)G′′(z)=n1z+n1z2+⋯+n1zn=n1z−1zn+1−z,=n1+⋯+n1=nn=1,=n(z−1)2nzn+1−(n+1)zn+1,=n(z−1)3n(n−1)zn+1−2(n+1)(n−1)zn+n(n+1)zn−1−2
For finding the mean and variance, G′(1) and G′′(1) are required but this makes the equations 0/0 when z=1. There exists a workaround. By Taylor’s theorem,G(1+z)=G(1)+G′(1)z+2!G′′(1)z2+⋯=1+G′(1)z+2!G′′(1)z2+⋯
Replacing z by z+1 in the original G function and connecting this Taylor’s series, G(1+z)=n1z(1+z)n+1−1−z=1+G′(1)z+2!G′′(1)z2+⋯
Since there is z in the denominator, the coefficient of z in G(1+z) is from the coefficient of z2 in (1+z)n+1 and the coefficient of z2 is from the coefficient of z3. As such, by comparing coefficients, G′(1)2!G′′(1)=n1(2n+1)=n1(n−1)!2!(n+1)!=n12(n+1)n=2n+1=n1(3n+1)=n1(n−2)!3!(n+1)!=n16(n+1)n(n−1)=6(n+1)(n−1)
Therefore, the mean m and variance V are as follows. mV=G′(1)=2n+1,=G′′(1)+G′(1)−G′(1)2=3(n+1)(n−1)+2n+1−4(n+1)2=(n+1)(3n−1+21−4n+1)=(n+1)12n−1
This is unstable situation. Generally, a distribution is called stable when the standard deviation is proportional to n and the difference between maximum and minimum is proportional to n.
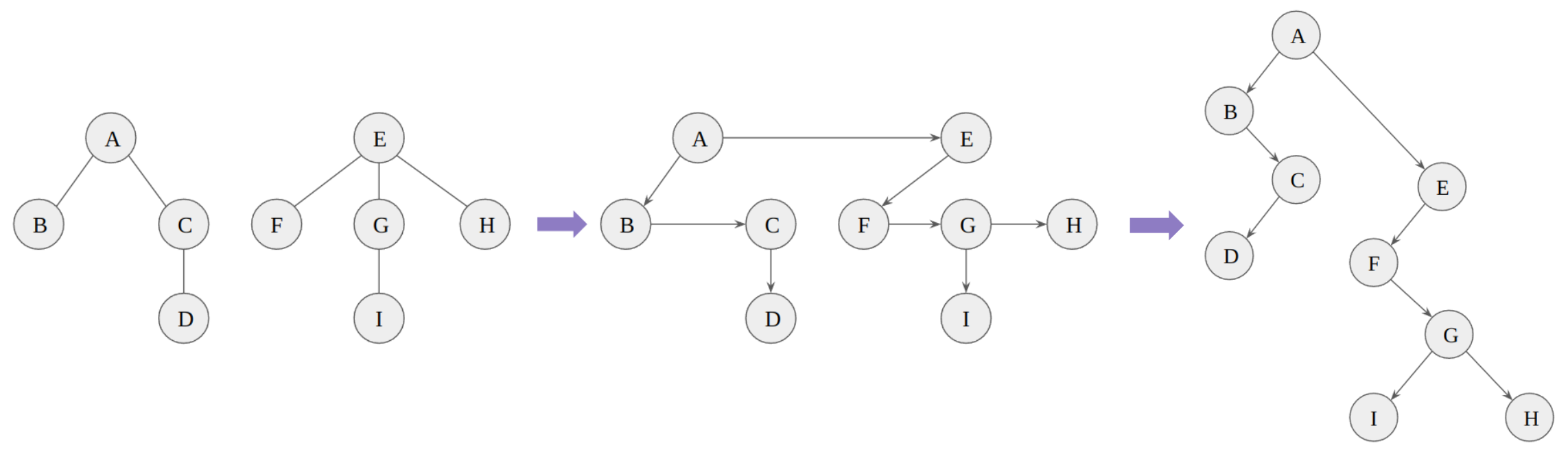
8. Any forest to a binary tree
There is a natural way to represent any forest as a binary tree.
Linking together the children of each family
Removing vertical links except from a parent to a first child
The final binary tree can be obtained after rotating the resulting tree. Note that any binary tree can be transformed into a unique forest by reversing the process.
9. Huffman algorithm to find a tree with minimum weighted path length
Given m weights w1, w2, ⋯, wm that are all real numbers, the problem is to find a binary tree and to associate the weights with its nodes in such a way that the sum ∑wjlj is minimized, where lj is the length of path from the root. The sum ∑wjlj is also called weighted path lengths. Huffman algorithm is an elegant algorithm for this problem. First find the two w’s of lowest value, say w1 and w2. Then solve the problem for m−1 weights w1+w2, w3, ⋯, wm. Every time this construction combines two weights, they are at least as big as the weights previously combined, if the given wi were nonnegative. This means that there is a way to find Huffman’s tree, provided that the given weights have been sorted into nondecreasing order. Using two queues, one containing the original weights and the other containing the combined weights, at each step the smallest unused weight will appear at the front of one of the queues. That is, there is no need to search for it. In general, there are many trees that minimize ∑wjlj. Furthermore, Huffman’s algorithm can be generalized to t-ary trees as well as binary trees.
Reference
[1] Donald E. Knuth, The Art of Computer Programming, Volume 1: Fundamental Algorithms
Keep going!Keep going ×2!Give me more!Thank you, thank youFar too kind!Never gonna give me up?Never gonna let me down?Turn around and desert me!You're an addict!Son of a clapper!No wayGo back to work!This is getting out of handUnbelievablePREPOSTEROUSI N S A N I T YFEED ME A STRAY CAT